Observability
Handling the unknown unknowns.
Cansu Kavili
What Is Observability?
In control theory, observability is the ability to determine how well the internal states of a system from the knowledge of its external outputs.
In software, observability is our ability to know and discover what is going on in our systems. It helps us to have a holistic view and deep understanding of our systems, identify issues faster, understand what caused the issue, and ultimately offer better customer experiences.
Why Do Observability?
Since systems are exponentially growing complex, things that can go wrong are increasing too. Often, we find ourselves looking for different answers to different questions from yesterday. This increasing complexity is why observability is so important and necessary today. Because an observable system allows us to ask any questions at any point in time and helps us to find our way from effect to cause.
Observability helps us to understand what’s slow, what needs to be optimized, when an error or an issue happens, and more importantly why.
An observable system can also tell us so many things, like:
- how our users use our products so that we can understand how to scope features and fixes
- what to prioritize next for features and fixes
- the code we ship deliver the value as we expect or not
So it also can help us answer questions about our users, validate (or invalidate) our ideas, and make decisions.
In other words, observability can give us a much deeper, shared understanding of our systems and what needs to be responded to quickly.
How to do Observability?
Observability focuses on asking any question about how the system works. That means we need to start asking questions and gather good data to be able to answer them.
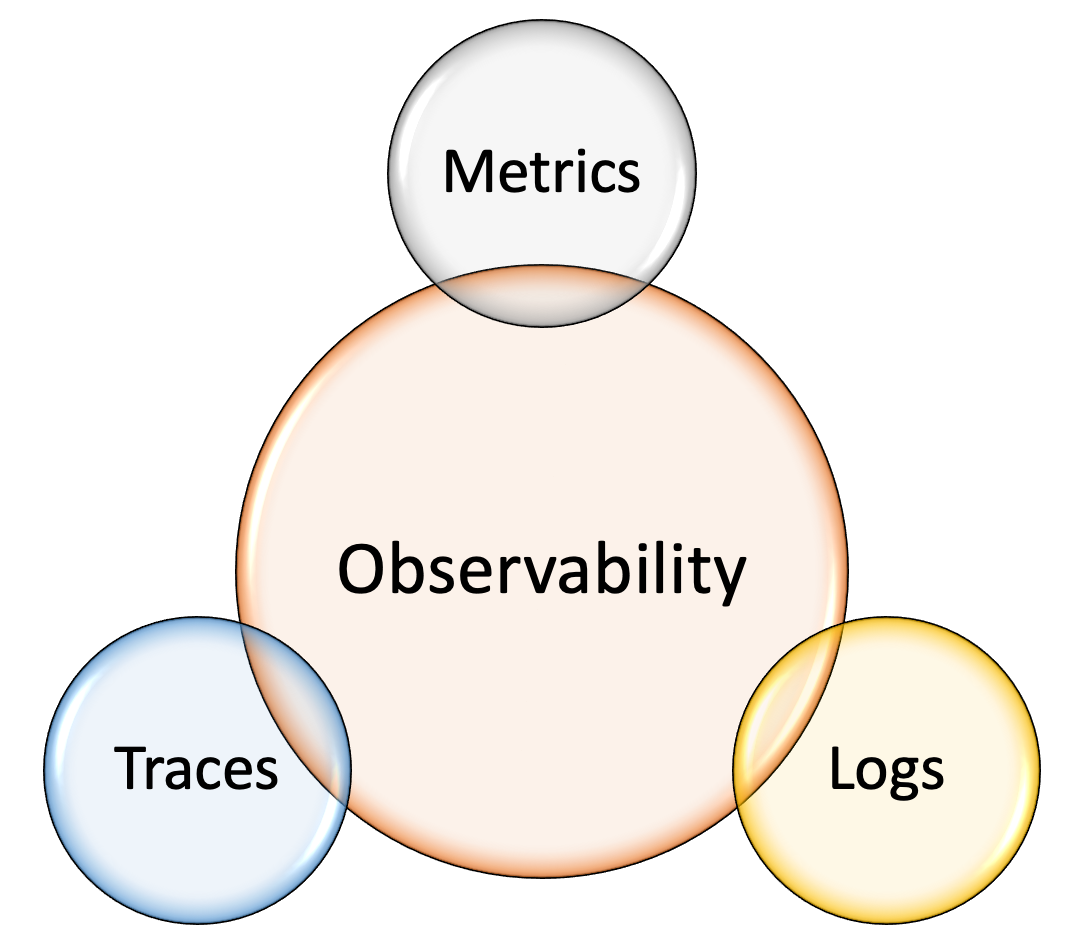
Traditionally, observability is a combination of telemetry data; metrics, logs, and traces (these are also referred to as the “three pillars of observability”).
- Metrics: is a measure of software characteristics that are quantifiable or countable. It might be how many requests per second are being handled by a given service, how much memory is being used, etc. Usually, metrics are the starting point and a great way to measure overall performance and health.
- Event: An event is a detailed record of something that the system did.
- Logs A log is an immutable, time-stamped, human-readable text of each event over time.
- Traces: A trace is a representation of a series of related events showing the end-to-end path of a single request or a transaction. Traces help us to identify the work done at each level, therefore, help us to identify latency along the path and which layer causes a bottleneck or a failure.
It doesn’t mean that these are going to be the only sources of information, but they are usually the main source of information. The important thing is to decide what is valuable and what does qualify for your systems. The next step is to correlate these different sources to be able to use them to quickly answer our questions. For example, using a unique request ID can get all the context from a user’s request at a specific point in time…like the time when the user complained but your monitors said things were all good.
Look at Observability
Links we love
Check out these great links which can help you dive a little deeper into running the Observability practice with your team, customers or stakeholders.